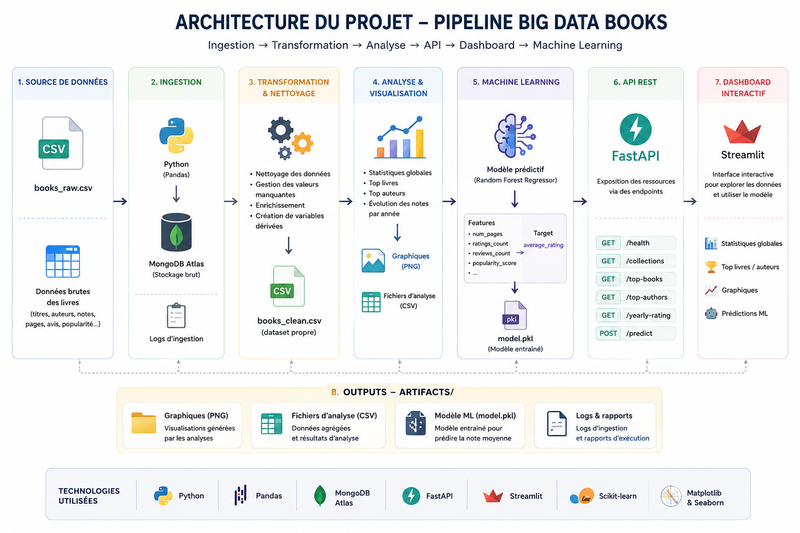
Pipeline de données complet sur un catalogue de livres : ingestion, nettoyage, analyse statistique et modèle de prédiction des notes. Les résultats sont exposés via une API REST et un tableau de bord interactif.
FIG. 01Architecture du pipeline BooksDataDe l'ingestion du catalogue au modèle de prédiction des notes, exposés via une API REST et un tableau de bord.
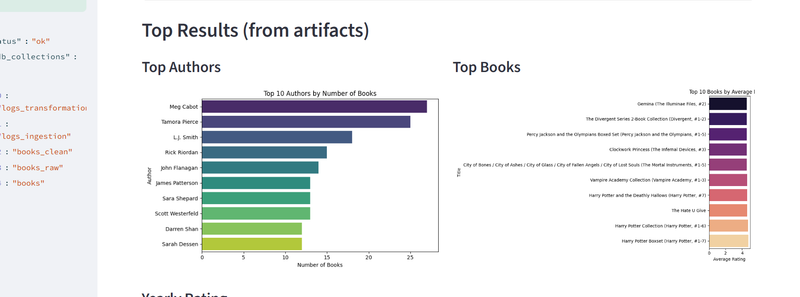
FIG. 02Dashboard interactif (Streamlit)Exploration des statistiques du catalogue et des prédictions dans une interface Streamlit.
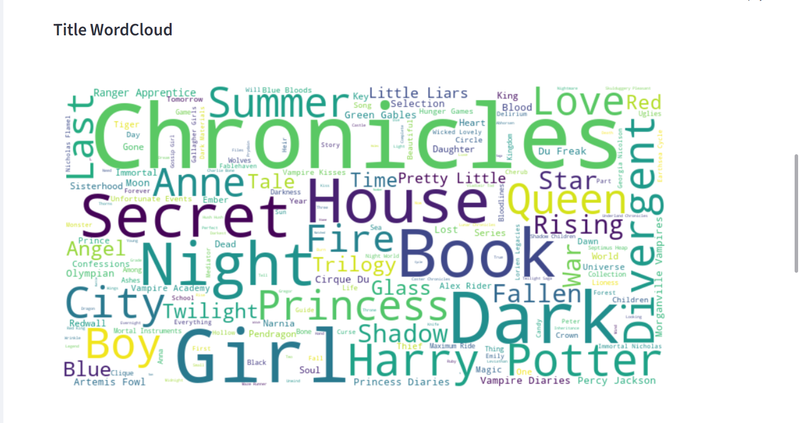
FIG. 03WordCloud des titres de livresAnalyse textuelle des titres pour faire ressortir les thèmes dominants.